Using Evaluations Offensively
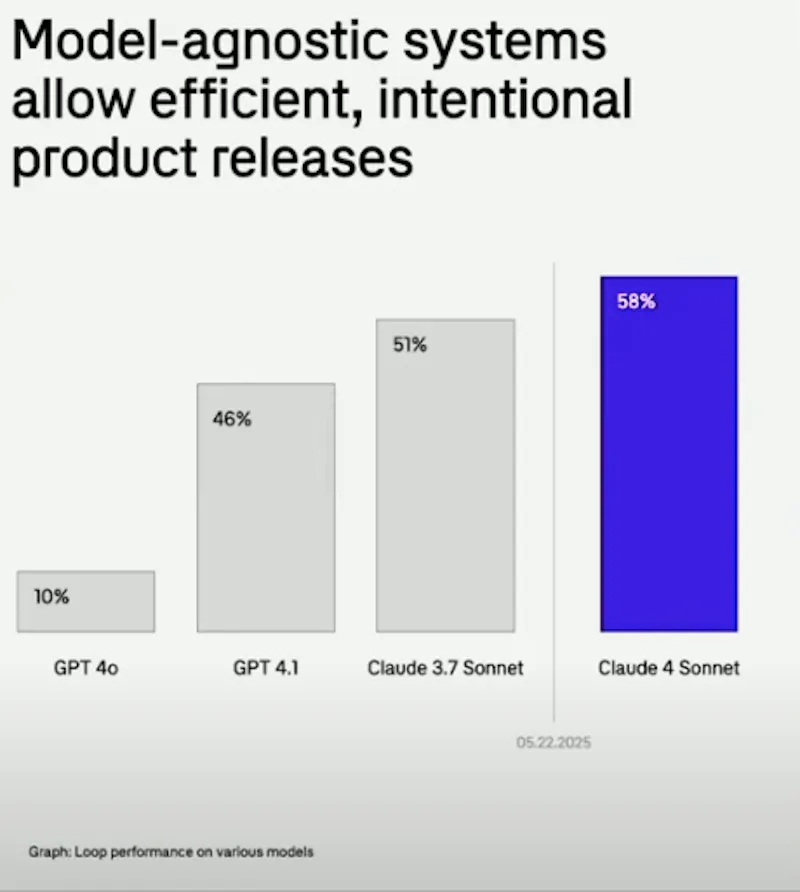
I just watched a presentation by Ankur Goyal at the AI Engineer's World's Fair, where he flips the idea of Evals-are-unit-tests-for-ai on its head.
Typically, we build a feature, then write some tests to protect it. When your tests fail in the future, you know you've broken something and need to fix it before pushing any changes.
This is true of conventional code as much as it is for evals.
Goyal suggested a more aggressive test-driven approach to evaluations.
You write the evaluations first, ambitious tests for features that AI might not be able to handle yet.
If the evaluations don't pass, you just keep the features on ice.
Every time a new model comes out, you get to run your evaluations and see if the system can handle what you were aiming for.
This is neat because it allows you to design based on what you need, not what's possible.
If what you need isn't possible, then you look for ways to break down, improve or simplify the feature (as you would have anyway).
The payoff is that the instant a new model comes out, you might get to drop all the workarounds and go straight for the capability you originally wanted.
Watch the whole presentation here...